转载自:https://zhuanlan.zhihu.com/p/21388517
论顺序的重要性 做饭的故事 今天女朋友加班,机智的她早已在昨晚准备好食材,回家只需下锅便可。谁知开会就是个无底洞,到了B1,还有B2,无穷匮也。
辛苦如她,为了能让她一回家就吃上热腾腾的饭菜,我准备亲自下厨,奉献出我的第一次。食材都已备好,我相信没有那么难,估摸着应该和我习以为常的流程处理差不多,开火 | 加食材 | 上配料 | 翻炒 | 出锅,啊哈,想想还有点小激动。
今天的晚饭是西红柿炒鸡蛋和胡萝卜炒肉,实际操作才发现,又遇到了一个大坑……
食材是这样的:
1 2 案板1号(西红柿炒鸡蛋的食材),从左向右依次放着:西红柿、鸡蛋、葱 案板2号(胡萝卜炒肉的食材),从左向右依次放着:蒜、胡萝卜丝、肉
食材在案板上整齐划一依次排开,我是先放西红柿呢,还是先放鸡蛋呢,还是先放葱呢?简单沟通后得知,案板上的食材是按顺序放好的,我只需要按顺序下锅即可。听着电视哼着90年代的老歌,三下五除二,两道菜如期完成。
闻着怪味,我知道第一次就这么失败了。
等她回家,一番检讨后,才知道是顺序放错了。每道菜都应该是从右往左依次放食材,即葱->鸡蛋->西红柿。这是逗我的么!?一般人所理解的按默认顺序不应该是从左往右嘛!
朋友们,到底应该是从左往右还是从右往左?
剥鸡蛋的故事 《格列佛游记》中记载了两个征战的强国,你不会想到的是,他们打仗竟然和剥鸡蛋的姿势有关。
很多人认为,剥鸡蛋时应该打破鸡蛋较大的一端,这群人被称作“大端(Big endian)派”。可是当今皇帝的祖父小时候吃鸡蛋的时候碰巧将一个手指弄破了。所以,他的父亲(当时的皇帝)就下令剥鸡蛋必须打破鸡蛋较小的一端,违令者重罚,由此产生了“小端(Little endian)派”。
老百姓们对这项命令极其反感,由此引发了6次叛乱,其中一个皇帝送了命,另一个丢了王位。据估计,先后几次有11000人情愿受死也不肯去打破鸡蛋较小的一端!
看到没有,仅仅是剥鸡蛋就能产生这么大的分歧,“大端”和“小端”有这么重要嘛!
字节序 字节 字节(Byte)作为计算机世界的计量单位,和大家手中的人民币多少多少“元”一个意思。反正,到了计算机的世界,说字节就对了,使用人家的基本计量单位,这是入乡随俗。
比如,一个电影是1G个字节(1GB),一首歌是10M个字节(10MB),一张图片是1K个字节(1KB)。
字节序 一元钱可以干嘛?啥也干不了,公交都不够坐的。一个字节可以干嘛?至少可以存一个字符。
当数据太大,一个字节存不下的时候,我们就得使用多个字节了。比如,我有两个分别需要4个字节存储的整数,为了方便说明,使用16进制表示这两个数,即0x12345678和0x11223344。有的人采用以下方式存储这个两个数字:
这个方案看起来不错,但是,又有人采用了以下方式:
蒙圈了吧,到底该用哪一种方式来存!两种方案虽有不同,但也有共识,即依次存储每一个数字,即先存0x12345678,再存0x11223344。大家的分歧在于,对于某一个要表示的值,因为只能一个字节一个字节的存嘛,我是把值的低位存到低地址,还是把值的高位存到低地址。前者使用的是“小端(Little endian)”字节序,即先存低位的那一端(两个数字的最低位分别是0x78、0x44),如上图中的第一个图;后者使用的是“大端(Big endian)”字节序,即先存高位的那一端(两个数字的最高位分别是0x12、0x11),如上图中的第二个图。
由此也引发了计算机界的大端与小端之争,不同的CPU厂商并没有达成一致:
x86,MOS Technology 6502,Z80,VAX,PDP-11等处理器为Little endian。
Motorola 6800,Motorola 68000,PowerPC 970,System/370,SPARC(除V9外)等处理器为Big endian。
ARM, PowerPC (除PowerPC 970外), DEC Alpha, SPARC V9, MIPS, PA-RISC and IA64的字节序是可配置的。
大端也好,小端也罢,就权当是个人爱好吧,只要你不影响别人就行,对不?
网络字节序 前面的大端和小端都是在说计算机自己,也被称作主机字节序。其实,只要自己能够自圆其说是没啥问题的。问题是,网络的出现使得计算机可以通信了。通信,就意味着相处,相处必须得有共同语言啊,得说普通话,要不然就容易会错意,下了一个小时的小电影发现打不开,理解错误了!
但是每个计算机都有自己的主机字节序啊,还都不依不饶,坚持做自己,怎么办?
TCP/IP协议隆重出场,RFC1700规定使用“大端”字节序为网络字节序,其他不使用大端的计算机要注意了,发送数据的时候必须要将自己的主机字节序转换为网络字节序(即“大端”字节序),接收到的数据再转换为自己的主机字节序。这样就与CPU、操作系统无关了,实现了网络通信的标准化。突然觉得,TCP/IP协议好任性啊有木有!
为了程序的兼容,你会看到,程序员们每次发送和接受数据都要进行转换,这样做的目的是保证代码在任何计算机上执行时都能达到预期的效果。
这么常用的操作,BSD Socket提供了封装好的转换接口,方便程序员使用。包括从主机字节序到网络字节序的转换函数:htons、htonl;从网络字节序到主机字节序的转换函数:ntohs、ntohl。当然,有了上面的理论基础,也可以编写自己的转换函数。
下面的一段代码可以用来判断计算机是大端的还是小端的,判断的思路是确定一个多字节的值(下面使用的是4字节的整数),将其写入内存(即赋值给一个变量),然后用指针取其首地址所对应的字节(即低地址的一个字节),判断该字节存放的是高位还是低位,高位说明是Big endian,低位说明是Little endian。
1 2 3 4 5 6 7 8 9 10 11 12 #include <stdio.h> int main () unsigned int x = 0x12345678 ; char *c = (char *)&x; if (*c == 0x78 ) { printf ("Little endian" ); } else { printf ("Big endian" ); } return 0 ; }
身边的字节序 字符编码方式UTF-16、UTF-32同样面临字节序的问题,因为他们分别使用2个字节和4个字节编码Unicode字符,一旦某个值用多个字节表示,就必须要考虑存储的顺序了。于是,采用了最简单粗暴的方式,给文件头部写几个字符,用来表示是大端呢还是小端:
头部的字符 编码 字节序 FF FE UTF-16/UCS-2 Little endian FE FF UTF-16/UCS-2 Big endian FF FE 00 00 UTF-32/UCS-4 Little endian 00 00 FE FF UTF-32/UCS-4 Big-endian
这里不得不提一下UTF-8啊,明明人家是单个字节的,不存在什么字节序的问题。微软为了统一UTF-X,硬生生给他的头部也加了几个字符!是的,这几个字符就是BOM(Byte Order Mark),这就是Windows下的UTF-8。
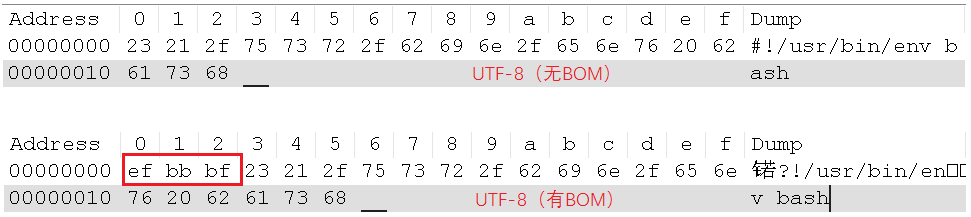
相信很多人都被UTF-8的BOM给坑过,多了这个BOM的UTF-8文件,会导致很多问题啊。比如,写的Shell脚本,内容为#!/usr/bin/env bash,在UTF-8有BOM和UTF-8无BOM的编码下,对应的16进制为:
所以,有BOM的话,Shell解释器就报错啦。原因在于,解释器希望遇到#!/usr/bin/env bash,而使用UTF-8有BOM进行编码的内容会多了3个字节的EF BB BF。
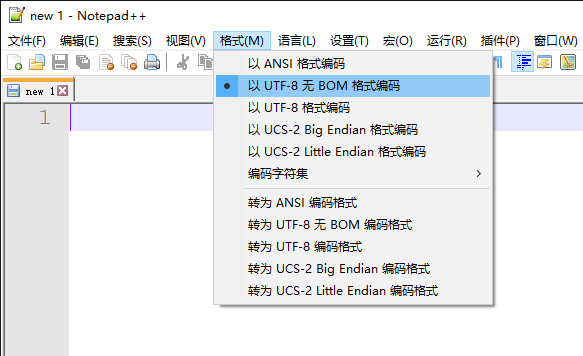
对于UTF-8和UTF-8无BOM两种编码格式,我们更多的使用UTF-8无BOM。