聊聊服务发现的推拉模型
前言
过去一年,我的工作重心投入到了 API 网关(阿里云 CSB)中,这对于我来说是一个新的领域,但和之前接触的微服务治理方向又密不可分。API 网关适配微服务场景需要完成一些基础能力的建设,其一便是对接注册中心,从而作为微服务的入口流量,例如 Zuul、SpringCloud Gateway 都实现了这样的功能。实际上很多开源网关在这一特性上均存在较大的局限性,本文暂不讨论这些局限性,而是针对服务发现这一通用的场景,分享我对它的一些思考。
概念澄清
服务发现这个词说实话还是有点抽象的,在微服务这一特定的领域具象化讨论才有意义。“服务发现”指的是“服务消费者获取服务提供者服务地址”的这一过程,而“服务”这一名词在不同微服务框架中代指也可能有所不同,不过大多数都是代指的应用、接口等信息。
- SpringCloud 以应用维度表示服务
- Dubbo2.x 以接口维度表示服务;Dubbo3.x 以应用维度表示服务
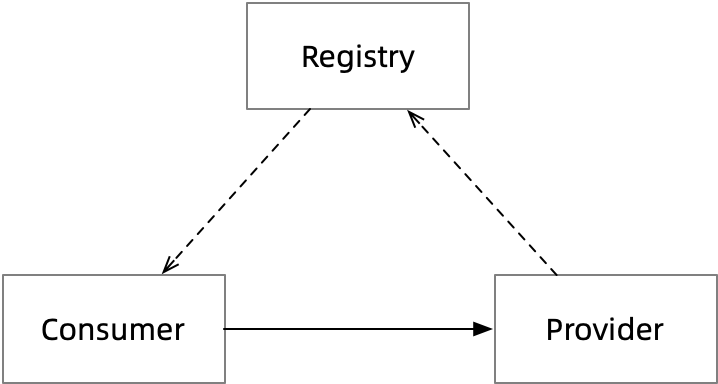
服务从 Provider -> Registry -> Consumer 的这一流动过程便是本文重点讨论的内容。
数据传递的两种方式:推模型和拉模型,一直是老生常谈的话题,在服务发现中也不妨一谈。 先不要急着回答服务发现这一场景中,推拉到底谁好的问题,让我们先看看一些微服务框架中的服务发现是如何实现的。
微服务框架中的服务发现
这一节以 Dubbo 和 SpringCloud 两个微服务框架为引子,看看它们的服务发现到底使用的是拉模型还是推模型。
Dubbo 服务发现
1 | public interface RegistryService { |
Dubbo 管理服务发现的核心接口 RegistryService 直接给出了答案,通过 subscribe 和 notify 这些关键字便可以猜测到 Dubbo 使用的是推模型。
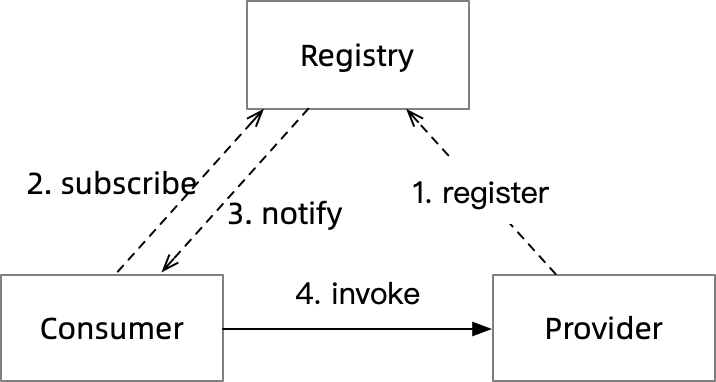
上图是一个推模型的工作流程。
SpringCloud 服务发现
1 | public interface DiscoveryClient extends Ordered { |
DiscoveryClient 是 SpringCloud 中一个核心服务发现的接口,通过 getInstances 基本可以看出,SpringCloud 使用的是拉模型。
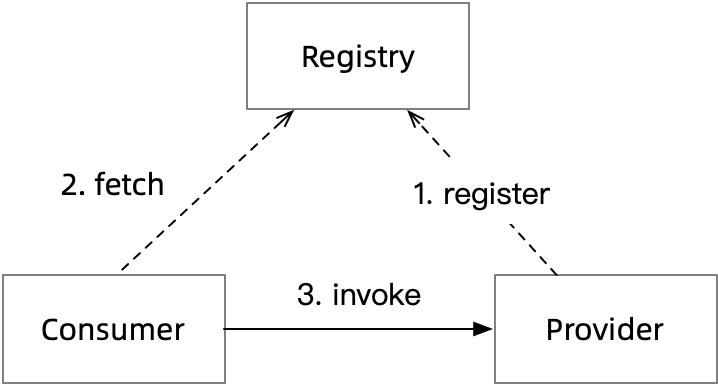
上图是一个拉模型的工作流程。
尽管我们还没有详细领略到两个模型背后的优化和实现细节,但从事实来看,Dubbo 和 SpringCloud 使用了不同的服务发现机制,都能让微服务玩转起来。
此时,如果你心里已经有了 Dubbo 是推模型,SpringCloud 是拉模型的认知,不妨再继续看下一节,可能这样的认知又会有了动摇。
注册中心中的推拉
上一节站在微服务框架的角度,介绍了服务发现的推拉模型,这一节则是站在注册中心的角度来分析。说到底,无论是 Dubbo 还是 SpringCloud,总得对接一款注册中心才可以获得服务发现的能力,可以是 Zookeeper,可以是 Nacos,可以是 Eureka,也可以是任意的其他提供了服务发现能力的组件。
我就先以 Nacos 为例介绍下它的推拉模型。先看 Nacos 的 Naming 模块提供的核心接口:
1 | public interface NamingService { |
为了方便阅读,我删除了大部分重载的接口以及非核心的接口。可以发现,从 API 角度,Nacos 是同时提供了推模型和拉模型两套接口的,这样也是方便其被微服务框架集成,有兴趣的读者,可以自行去阅读下 Dubbo/SpringCloud Alibaba 集成 Nacos 的代码,Dubbo 使用的便是 subscribe 这一套推模型的接口,SpringCloud Alibaba 则是使用的 selectInstances 这一套拉模型的接口。
那是否说”Nacos 是一个推拉模型结合的注册中心”呢,不够严谨。且看 getAllInstances,selectInstances 这两个方法都有一个 subscribe 入参,跟一下源码探究一下
1 | public List<Instance> selectInstances(String serviceName, String groupName, List<String> clusters, boolean healthy, |
可以发现 subscribe 这个参数控制的是是否直接从注册中心拉取服务,subscribe=false 时,实际是从 Nacos 自身维护的一块本地缓存中获取到的服务,大多数情况下,获取服务使用的是 subscribe=true 的重载方法。所以,selectInstance 看起来是在拉服务,subscribe 看起来是在推服务,实际上 Nacos 内核维护缓存的方式我们并未得知。
从上述 subscribe 的提示中,我们可以得出结论,我们并不能直接通过个别接口就得出该注册中心使用的是推模型还是拉模型,究竟何种模型,还是要看 client 端是如何从 server 端加载/更新服务信息的。
那么,真实情况下,Nacos client 究竟是如何从 server 端获取到服务列表的呢?也不卖关子了,直接给结论:
在 Nacos 1.x 中,Nacos 采用的是定时拉 + udp 推送的机制。客户端会启动一个定时器,每 10s 拉取一次服务,确保服务端服务版本一致,为了解决 10s 间隔内服务更新了,客户端却没有及时收到通知的这一问题,Nacos 还在服务端服务更新时,触发了一次 udp 推送。
在 Nacos 2.x 中,Nacos 采用的是服务端 tcp 推送的机制。客户端启动时会跟服务端建立一条 tcp 长连接,服务端服务变更后,会复用客户端建立的这条连接进行数据推送。
所以在回答,Nacos 到底是推模型还是拉模型时,需要区分版本来回答。
结论:Nacos 1.x 是拉模型;Nacos 2.x 是推模型
不知道有没有读者好奇 Nacos 为什么这么设计,我简单用一些 QA 快速解答一些可能的疑问:
Q:为什么 Nacos 1.x 使用了 udp 推送,却把 Nacos 1.x 定义为拉模型?
A:Nacos 1.x 中 udp 推送主要是为了降低服务更新延时而设计的,并且在复杂网络部署架构中,例如 client 与 server 只能单向访问,或者有 SLB 中间介质时,udp 就会失效;且 udp 本身就是不稳定的,Nacos 尝试两次失败后就会放弃推送。所以主要还是在用拉模式来保障。
Q:为什么 Nacos 1.x 一开始不使用 Nacos 2.x 中的架构,使用 tcp 推送?
A:个人猜测是因为拉模型实现起来简单,Nacos 2.x 才引入了 grpc 实现长连接
Q:为什么 Nacos 1.x 的服务发现使用的是短轮询,不像配置中心那样使用长轮询?
A:在服务发现场景中,服务端比较在意内存消耗,长轮询虽然不会占用线程,但服务端依旧会 hold 住 request/response,造成不必要的内存浪费。
一些常见注册中心的推拉模型:
- Zookeeper:推模型
- Nacos 1.x:拉模型
- Nacos 2.x:推模型
- Eureka:拉模型
好,介绍完了注册中心视角的服务发现推拉模型了,再回过头来看一个问题:如果使用了 SpringCloud Alibaba + Nacos 2.1 版本,那它的服务发现就是走的哪种模型呢?
正确答案:在微服务框架视角,sca 走的是拉模型这种同步拉取服务的机制;在注册中心视角,应用作为客户端是使用的推模型在接收服务变更的推送。
那有一部分比较帅的人可能会有问了,到底什么模型比较好呢?哎,下面就容我对比下二者。
推拉对比
实时性
服务推送的实时性是服务发现主要的 SLA 指标,其指的是当服务地址发生变化时,客户端感知到变化的延迟。试想一下,服务端正在发布,IP 地址发生了变化,但是由于地址推送不及时,客户端过了 10 分钟还在调用旧的服务地址,这是多么可怕的一件事。
拉模型感知服务变化的延迟便是短轮询间隔+拉取服务的耗时,在 Nacos 中,SLA 为 10s。
推模型感知服务变化的延迟则为服务端推送服务的耗时,在 Nacos 中,SLA 为 1s。
在实时性上,推模型有较大优势。
压力
拉模型和推模型都会对服务端造成压力,但是二者的时机不同。
- 拉模型的压力是固定的,取决于轮询间隔。
- 推模型的压力取决于服务变更的频率。
用两个场景来做对比:
- 常态化场景。日常运行时,服务列表一般不会变化,拉模型会导致不必要的开销,对服务端造成较大压力。
- 快上快下场景。机器快速扩容或者缩容,导致服务地址频繁变更,推送量会瞬时变大,对服务端和客户端造成较大压力。
针对快上快下场景,也可以进行一系列的优化,例如推送合并,增量推送,数据分离等等,目前 Nacos 支持了推送合并这一优化。
代码复杂度
码龄越大,越发意识到代码复杂度是一个非常重要的技术选型指标,越简单的代码越容易维护,也具备持久的生命力,架构师需要在代码复杂度和性能的 trade off 中,找到一个平衡点,不得不承认,推模型的复杂度往往要比拉模型高出很多,例如多出了长连接的状态管理这一环节。
拉模型完全胜出。
总结
这篇文章不希望大家陷入到字眼中,判断某一个框架或者工具是推或者拉模型,而是希望能介绍清楚服务发现中推拉模型的工作流程,方便大家对这些微服务框架也好,注册中心也好,有一个更深的理解。
总结一下,主流的微服务框架和注册中心的服务发现机制中,推模型和拉模型均有使用,具体如何选择,如何优化,可以根据自身服务的特点,以及服务的规模去选择使用。
在我负责的 API 网关(阿里云 CSB)中,采用了一套独立的服务发现机制,同时支持拉模型和推模型,以适配部分仅支持推模型或者仅支持拉模型的注册中心。
聊聊服务发现的推拉模型


