使用 Qoder 2 个月,我总结了一些经验
大家好,我是岛风。订阅了两个月 Qoder 之后,我想通过这篇文章分享一些个人使用心得和感受,希望能和大家交流 AI 编码的经验。
Qoder 是什么

Qoder 是阿里在 Agentic Coding 赛道上交出的一份答卷,一个对标 Cursor、Claude Code 的智能编码平台。官网链接:https://qoder.com/referral?referral_code=giB4Qp8oAraMl3HnoBEqCoIavUwbZJPO
目前提供了几种不同的形态供用户选择
Qoder IDE:一个独立的、拥有图形化界面的 IDE,核心功能包括 Agent 模式、问答模式、Quest 模式。
Qoder CLI:命令行工具,为喜欢终端操作的开发者准备。
Qoder JetBrains 插件:对于离不开 JB 全家桶的开发者,Qoder 提供了无缝集成的插件。
我为什么用 Qoder
AI Coding 产品作为一个消费级的产品,除去公司采购报销场景,自行使用基本都是付费上班模式,所以还是会用脚投票的。
公司已经对部分部门开放了 Cursor 的申请入口,但很不巧我所在的部门还没有开放申请入口。
于是便采取了比价模式,以 Curosr 和 Qoder 对比为例,二者同样采取订阅制,同样的 Pro 订阅 Qoder 的价格是 Curosr 的一半,再叠加上新用户赠送 2000 credits 和首次订阅 2 刀的“真香”福利,不动心真的很难。
至于为什么没考虑其他工具:
- Claude Code。口碑虽好,但国内使用据说极易被封,加上公司强大的安全扫描,用“黑科技”强行上车,风险未知,得不偿失。
- 字节 Trae 和美团的 Catpaw。主要是产品成熟度和友商因素。在没有形成压倒性口碑之前,没必要投入太多精力去“陪跑”。
聊聊 AI Coding
尽管 Agentic Coding 的产品早已从蓝海卷成了红海,但就我观察,周围同事的接受度并不算高。和几位同事聊下来,他们不用的原因主要集中在两点:
- 安全合规的顾虑:担心公司内部代码库使用海外大模型有安全问题,但其实公司安全已经明确了该政策:C1 直接使用,C2 按需使用,只有 C3 明令禁止,这意味着大部分项目都能放心用。
- 习惯的力量:习惯了 ideaTALK 的对话模式,一分钱不用花,CV 一下也能体验最新大模型带来的提效。
但我坚信,他们只要真正上手用一次 Qoder,心里一定会冒出那句话:“为什么没人早点告诉我?”
AI Coding 带来的体验,和自动驾驶给人的冲击感很像——一个开惯了油车的老司机,第一次体验到 L2 辅助驾驶,那种“相见恨晚”的感觉。这一切,只取决于用户什么时候愿意迈出那一步,打破固有的思维定式和肌肉记忆。
使用经验分享
经验 1 - 熟悉界面,更是切换思维
刚上手 Qoder,最大的障碍不是技术,而是习惯。因为安利过同事使用 Qoder,我能深刻感受到一个已经熟悉了 IntelliJ IDEA 的 Java 研发在面对一个全新的 Qoder IDE 时的无措:这个对话窗口关闭了怎么打开?上下文达到多少需要压缩?添加上下文里面出现的这么多 @xxx 都是干嘛用的…
这个问题的本质是,传统的 IDE 是一个“文件浏览器 + 编辑器”,我们的思维是在文件树里“导航”和“定位”。而 Qoder 的核心是“以对话为中心的上下文管理器”。需要把思维从“我要去哪个文件里改代码”转变为“我需要告诉 AI 哪些信息,才能让它帮我改代码”。
Qoder 主界面常用功能:
- 问答模式 → Ask Mode:用于代码理解,不会触发代码编辑。
- 智能体模式 → Agent Mode:理解任务,自动规划,读写文件,执行命令,自主完成编码工作。这是最高频使用的模式。
- Quest 模式:专为复杂任务设计。通过“设计先行”的理念,先通过多轮对话敲定方案文档,再拆分任务、自动执行,最后产出代码和总结。这是 Spec Driven 开发理念的最佳实践。
- 添加上下文:这是保证代码生成质量的关键。手动添加上下文,能让 AI 精准地理解你的意图,避免它“自由发挥”导致影响范围过大。
- @file: 引用一个或者多个文件
- @folder: 引用一个或者多个文件夹
- @codeChanges: 引用 Git 暂存区的代码变更。非常适合在提交前让 AI 帮忙 Code Review 或补单测。
- @gitCommit: 引用某个 commit 提交记录。可用于问题排查和缺陷修复。
熟悉 IDE 布局和这些核心概念,是克服对 Qoder 陌生感的第一步。一旦跨过这个坎,就真的回不去了。
在开发后端时,我会 mac 打开 Qoder、显示器打开 IntelliJ IDEA,一些 IDEA 的习惯还是摆脱不了;在开发前端时,我会直接使用 Qoder。
经验 2 - 问答模式 + 智能体模式
问答模式和智能体模式是我最常用的功能。在处理需求时,我习惯先 Ask(提问)再 Agent(行动)。先通过问答模式摸清存量代码的脉络,再切换到智能体模式动手开干。
Qoder 真正让人上瘾的原因,在于它的 Agent 模式已经迈过了某个“拐点”,在效率、成本、代码质量和易用性上达到了一个让人满意甚至惊叹的平衡点。
当然,Agent 模式也会判断用户意图,如果它觉得不需要改代码或有多种选择,会先跟你确认。但出于成本考虑,当你明确知道只是想问问、不需要它动代码时,还是建议手动切到 Ask 模式。
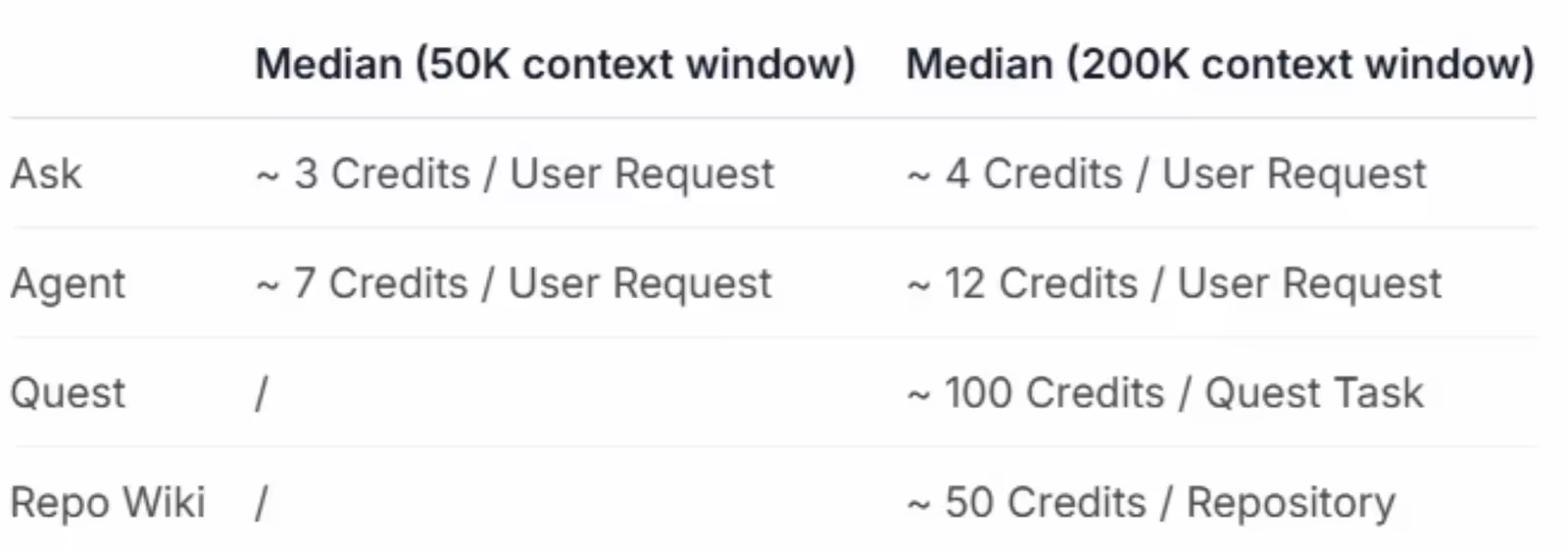
注:图中主要展示的是消耗平均数,并非真正意义上按次数收费,Quest 模式在我实测下来消耗大概在 50 credits 以下,图中显示 100 credits 大概率是有人来拿 Quest 模式许愿了。
在安利同事的过程中,我被问得最多的一个问题是:“你是怎么向 Qoder 提问的?”
这确实有点“玄学”的味道。我能感觉到自己越用越顺手,能把握住什么时候一句话描述需求,什么时候需要补充复杂的上下文。但“如何提问”这个问题的答案,其实贯穿了整篇文章,它是一个组合技能,包括:
- 提示词(Prompt)如何优化?
- 上下文该如何引用?
- 如何判断上下文窗口的健康度?
- 什么场景该用什么模式?
- …
再多的方法论,也不如一次成功的实践来得真切。AI Coding 的效果好坏,很多时候只可意会,不可言传。
经验 3 - 上下文管理:投喂的艺术
上下文管理,主要对应 Qoder 界面上的“添加上下文”和“压缩上下文”。
“添加上下文”是一个能显著提升幸福感的好习惯。它能有效减少 AI 在工程中“盲搜”的负担,让它一次性把事情做对。虽然不手动添加,Qoder 强大的代码检索能力也常常能定位到目标文件,但这个过程毕竟是个黑盒,检索质量和最终的修改范围都充满了不确定性。
通过 @file/@folder/@codeChanges 手动添加上下文一定是一个好的习惯,最常用的就是添加几个核心文件或关键代码片段。你也不需要把所有相关文件都加上,只要提供了核心线索,模型和工具就能顺藤摸瓜,大大提升命中率。
上下文管理也有其他的表现形式,例如 Qoder 提供的 Repo wiki,以及下文会介绍的记忆和规则,都是对上下文的补充,提供足够的上下文信息给到模型,往往能达成最让你满意的结果。
而对于“压缩上下文”,我的态度是敬而远之。相比压缩功能本身,我发现观察上下文窗口的占用比例更有价值。
这个占用比例是一个绝佳的任务复杂度“指示器”。如果一个任务聊了几轮后,上下文窗口就飙升到 60% 以上,这其实是 Qoder 在向你发出信号:“这个任务太大了,不适合在 Agent 模式下一次完成,需要进行拆分!” 这时,我宁愿新开一个窗口处理子任务,也不会选择压缩上下文。
为什么不压缩?主要是担心信息失真。压缩算法是个黑盒,我无法确定关键信息是否在压缩中被“优化”掉了,万一它“取其糟粕,去其精华”呢?
最后还是绕不开成本。Qoder 的 credits 计费模式最终还是会跟 Token 总量挂钩,过长的上下文也会带来 credits 焦虑。所以,保持上下文的“精简”和“健康”,既能保证质量,又能节省开销。
这里要特别提一下基础模型。我在 Qoder 交流群里看到不少人还在用基础模型。基础模型最大的瓶颈就是上下文窗口太小,一个原子任务还没做完,窗口就爆了。如果你正在用基础模型体验,请务必知道,这只是模型的上限,不是 Qoder 的上限。
经验 4 - Quest 模式:谋定而后动
Quest 模式专为复杂任务而设计,它遵循一个简单的三步原则:设计 → 执行 → 总结。
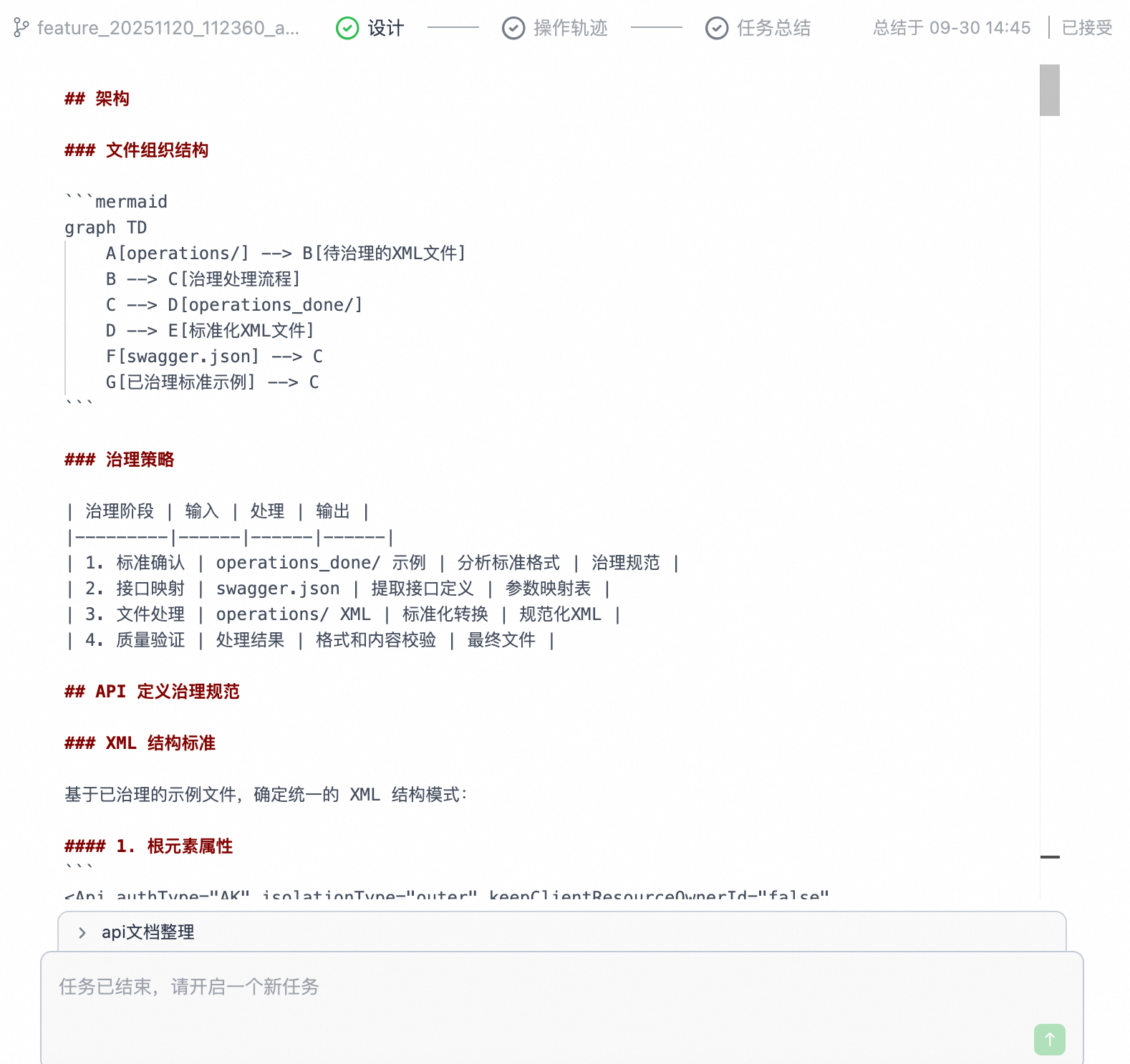
直接用 Agent 模式处理复杂任务,常常会遇到两个问题:
- 下发一个复杂任务,Agent 拆解出 A、B、C、D 四个待办。结果它可能只执行了 A 和 B,然后告诉你 C 和 D 留着下次再做,任务被中断。
- 复杂任务导致上下文窗口迅速膨胀,因为 Agent 模式要同时兼顾意图识别、代码阅读、方案设计和编码,压力山大。而用户手动拆分任务又缺乏连贯性,相当于把上下文存在了自己的脑子里。
Quest 模式巧妙地解决了这个问题。它将“思考”和“执行”分离:先通过多轮对话,和你一起打磨一份 Markdown 格式的设计方案,一旦方案敲定,AI 就能心无旁骛地按照一次性执行到底。
Quest 模式的优点显而易见:
- 践行了 Spec Driven 开发理念,Markdown 文档就是 Spec。
- 强迫你“想清楚了再干”,避免了大量返工。
- 支持远程执行和委派,你可以把任务交给它,然后去忙别的。
经验 5 - Git Commit
我从未想过,Git Commit 的哲学跟 AI Coding 之间有如此大的默契。
在此之前,一个多人协同开发的内部项目中,很容易看到一堆不规范的 commit message,诸如:
- “修复了一些 bug”这种毫无意义的提交信息
- 不符合 Angular 的 commit 规范
feat(user): add login api - 一次 commit 包含了过多的内容,导致 code review 难度很大
在 Qoder 的加持下,自动生成 commit message 这个小功能发挥了绝大的价值。而 Cursor 对中文生成 commit message 支持不佳,导致我即使在 Curosr 里写完了代码,也忍不住要切回 Qoder 来生成 commit message,意料之外地提升了用户粘性。
当你的 git log 变得规范后,好处是连锁的:
- 可以和
@gitCommit功能联动,精准回溯。 - 改坏了代码手滑接受了?至少还有一个清晰的回溯点。
- 通过 commit message 就能快速理解同事的工作,沟通成本大降。
经验 6 - 规则(Rules) & 记忆(Memory)
规则 (Rules) 是项目级的“铁律”,你可以把项目的强制规范写进去,让 Qoder 严格遵守。
rules 文件会保存在 .qoder/rules 目录下,所以团队协作时,切记不要把 .qoder 目录加到 .gitignore 里。
目前我们的前端项目加了不少规则,比如:
- 国际化规范: 约定模型只提供包含中文文案的代码,后续交给脚本统一扫描翻译。
- 组件库规范: 强制使用我们专有云的 Teamix 组件库。
- 命名规范: 统一变量和函数的命名风格。
- 私域知识: 内置一些体量不大的内部知识。
规则的一些最佳实践:
- 保持简洁:让规则聚焦且明确无歧义。
- 结构清晰:使用项目符号、编号列表或 Markdown 格式以提升可读性。
- 包含示例:提供“良好”的代码示例以指导模型。
- 迭代与优化:根据模型输出和反馈不断完善规则。
规则和记忆都属于 Qoder 预置的上下文,二者的主要区别:
- 规则属于项目级,记忆属于用户级。
- 当规则与记忆冲突时,规则优先。
- 规则需要手动维护,记忆则分为主动记忆和自动记忆。我个人主要使用自动记忆,不太会主动管理记忆,只有当发现记忆出了明显问题时,才会手动清理。
自动记忆功能用好了,会让你产生一种“Qoder 越来越懂我”的感觉。它记住了你的编码习惯和偏好,即使你在多个项目或窗口间切换,也能减少大量重复描述背景的麻烦。
经验 7 - 划清模型和工具的边界
理解哪些任务应该交给模型,哪些任务应该让模型帮你创造一个“工具”来解决,是掌握 AI Coding 进阶能力的一个依据。
大模型是概率工具,不是逻辑引擎,它擅长创造和模仿,但不擅长精确和重复。且模型存在上下文窗口限制和幻觉。
基于这个认知,我的原则是:一次性的、创造性的任务交给模型;需要重复的、确定性的任务,让模型帮我创造一个工具来解决。
下文的 swagger2xml 案例就是这个原则的最佳体现。我没有让 AI 一遍遍地帮我把代码“翻译”成 XML,而是让它一次性地帮我“创造”一个翻译工具。这个工具是确定性的、可重复使用的、高效的。用 AI 的“创造力”,完美解决了它自身“一致性”不足的问题。
经验 8 - 质量保障:警惕 “Vibe Coding”
在维护开源项目 Higress 的过程中,我观察到一种因 AI 产生的坏味道——“Vibe Coding”。一些社区贡献者提交了 AI 味很浓的代码,但缺少必要的方案设计和自我验证,导致审查的压力全都转移到了 Reviewer 身上。
我曾在社区吐槽这个现象:Developer vibe coding → Reviewer vibe review → Developer vibe fix → A vibe project.
对于存量项目来看,依靠存量的 UT 和 CI 来对 AI Coding 产出代码的验证是一个兜底方案,同时也给质量保障带来了一个新的哲学话题,如果保障 AI Coding 的质量?
AI Coding 带来的效率提升,也对研发人员提出了新的素养要求,我们需要建立新的质量保障体系:
- 可测试性优先: 尽早将“代码必须可测试”这一准则加入到
rules中,从源头上避免 AI 生成无法进行单元测试的代码。 - 谨慎“全局接受”: Agent 模式一次性生成大量代码后,很容易有“一键接受”的冲动。但 Qoder 目前不支持撤销,一旦接受就无法回头。建议还是文件 by 文件进行审查和接受。
- 推行 Prompt Review: 在 Higress 社区,我们已经开始尝试这一举措。对于有明显“Vibe Coding”痕迹的提交,要求贡献者附上他的核心 Prompt。在开源社区这种异步协作的环境下,Prompt Review 极大地保护了 Reviewer。Qoder 未来或许可以考虑推出一个“一键生成提示词摘要”的功能。
案例分享
案例 1 - swagger2xml 工具
需求: 将一个 Spring Boot 项目 Controller 层的接口,自动生成符合内部 API 平台规范的元数据 XML 文件,用于补充 API 文档。
我的弯路: 最初,我想直接让 Qoder 基于模型能力,逐个接口生成最终的 XML 文件。
踩到的坑:
- XML 格式一致性难以保证,AI 时不时会“自由发挥”。
- 消耗大量 credits,成本高。
- 上下文窗口容易爆炸。
- 一次性工作,无法复用。
我的转向: 回到“经验 7”的原则,我让 Qoder 帮我创造一个工具:一个专门用于生成元数据的小项目。这个项目 99% 的代码都是由 Qoder 完成的。这完美体现了“用 AI 造工厂”的思路。
案例 2 - 专有云 AI 网关模型/MCP 大盘前后端联调
Qoder 目前没有直接的跨工程管理能力,如果前后端两个 Git 仓库需要同时修改,会有些不便。
我的工作流是:后端开发完成后,用 Quest 模式生成一份详细的对接方案(包含接口地址、参数、返回格式等)。然后,在前端项目中打开这份方案,再用 Quest 模式完成接口的对接和调试。Qoder 在这个过程中,像一座桥梁,助力后端程序员轻松跨界,搞定前端的活。
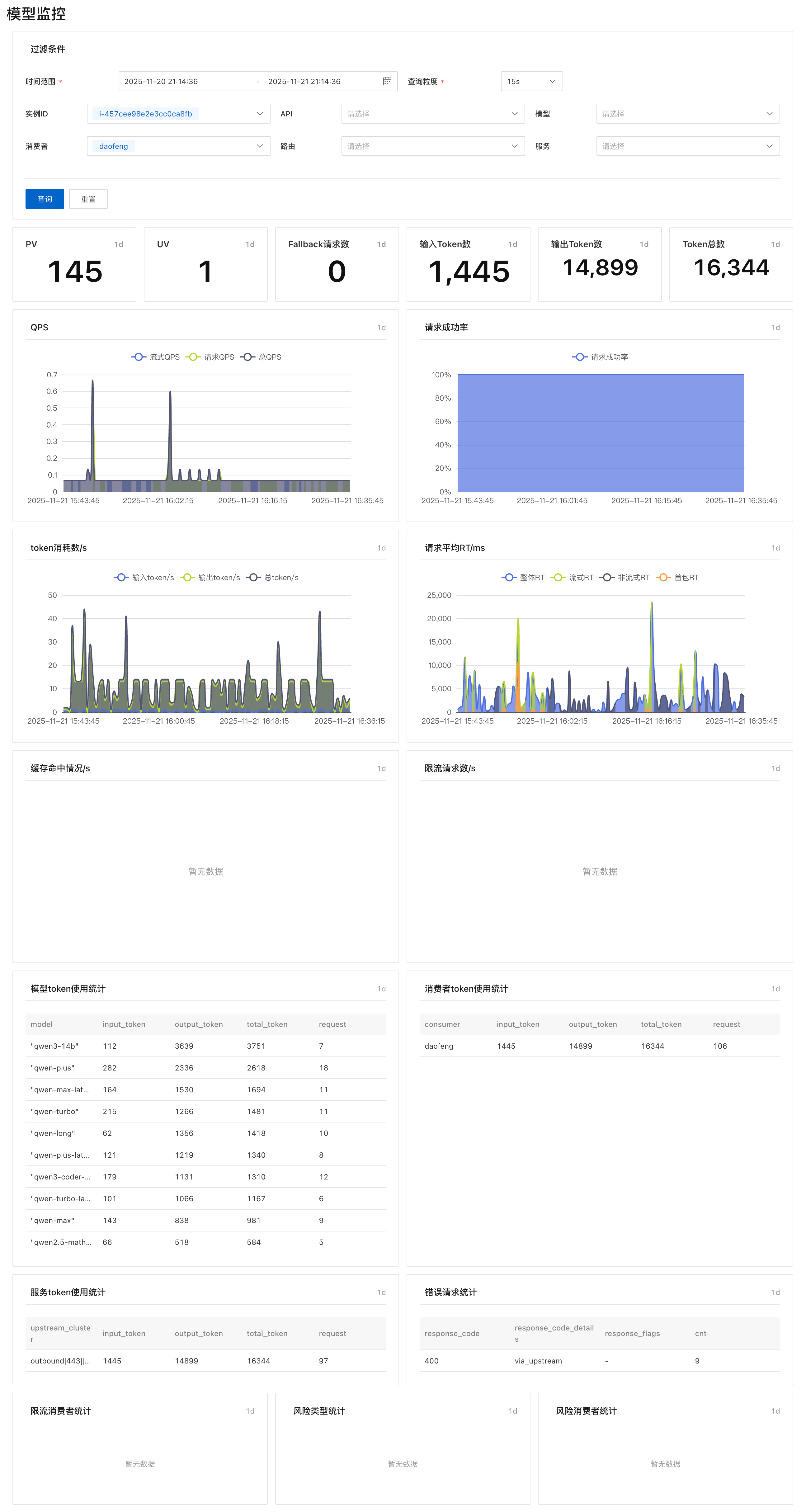
借助 Qoder,从数据埋点、到数据查询,到前端大盘绘制,都是自己跟自己联调,还大大降低了沟通成本,编程语言和岗位职责已经不再是能力的边界,想象力才是。
案例 3 - 私域知识感知
我们使用的前端组件库是 Teamix,它存在文档缺失、本身闭源的问题,模型在预训练阶段根本没见过它,因此直接让 Qoder 写相关的前端代码非常困难。
我的解法: 将 Teamix 已有的前端文档和代码示例,作为普通文件补充到项目中,然后在 rules 里引导模型去引用这些文档。
这个案例反而让我深刻体会到了开源的优势,如果非核心代码资产,仅仅是工具,非常适合开源开放,这会倒闭维护者完善文档,同时被大模型预训练,让 AI 天生就更懂你。
AI Coding 展望
AI Coding 解决了传统开发的诸多问题,大幅提升了生产效率,也产生了一些方法论,但形成体系的最佳实践还没有明显的共识,Agentic Coding 产品本身也还在激烈竞争中。
啥时候 Qwen 系列模型能跻身到极致性能之列,很期待这一天的到来。

使用 Qoder 2 个月,我总结了一些经验


